Prelude
Go supports XML processing in the standard library package encoding/xml. The Marshal and Unmarshal function will use a Encoder and Decoder under the hood, as these are more general.
With a Decoder it is possible to iterate over a large number of XML elements and to deserialize data in a way that will limit memory consumption. Here is a playground example for using a decoder to repeatedly parse elements from a Reader: efY60PYLFm8.
One limitation of this approach is that you can only parse top-level elements. This restriction is circumvented by utilities like xml-stream-parser or xmlstream, which allow to parse a number of different elements from any level in the XML document in a streaming fashion.
Performance
XML decoding is slow, less because Go is slow (it usually is not), but because parsing it can be expensive (you can also try to use libxml with CGO to make it faster). After all, XML is a markup language, it can do things JSON cannot do (like TEI). Surprisingly, many real world uses of XML can be covered by JSON just as well. As a result, we can observe a decline in XML usage and a de-facto standard choice of JSON for lots of data exchange tasks and implementations (according to google trends, the term JSON surpassed XML in January 2016).
As data work often involves an ad-hoc data scouting step (with tools like jq, or duckdb), some variants of JSON gained popularity, like jsonlines (also called JSON streaming or newline-delimited JSON). You can continue to use many UNIX text utils, while enjoying all the features of RFC 8259.
A format like jsonlines then makes it easy to parallelize JSON transformation tasks with a fan-out, fan-in pattern: Read N lines, pass batch to goroutine, collect results and write them out. A tool like miku/parallel (“fast filter”) allows to abstract away some of the parallel processing boilerplate (example of extracting a value from jsonlines, twice as fast as jq).
No lines for XML
XML does not have a widely used, line oriented representation (there is PYX, an early attempt at XML streaming). How can we still process XML faster than iterating through it sequentially? We have to parallelize it, but instead of relying on a newline for delimiting records, we have to isolate the elements we are interested in, and batch hand them over to processing threads. There is already a suitable type in the standard library to split a stream into tokens.
A Scanner quickly
The bufio.Scanner shows the utility of first class functions for customizing type behaviour (another example is Proxy in http.Transport). We can implement a custom SplitFunc that would split a stream on XML tags.
Since we only want the element boundaries, parsing the input stream is much faster, as all we need to do is to find the Index of the start and end tags in the stream. Following the optimization by batching, we can collect N elements or put a (soft) limit on the number of bytes in a batch and then pass a chunk of valid XML to a processing function, which then can run in parallel and do the heavy lifting of proper XML parsing.
Splitting on tags
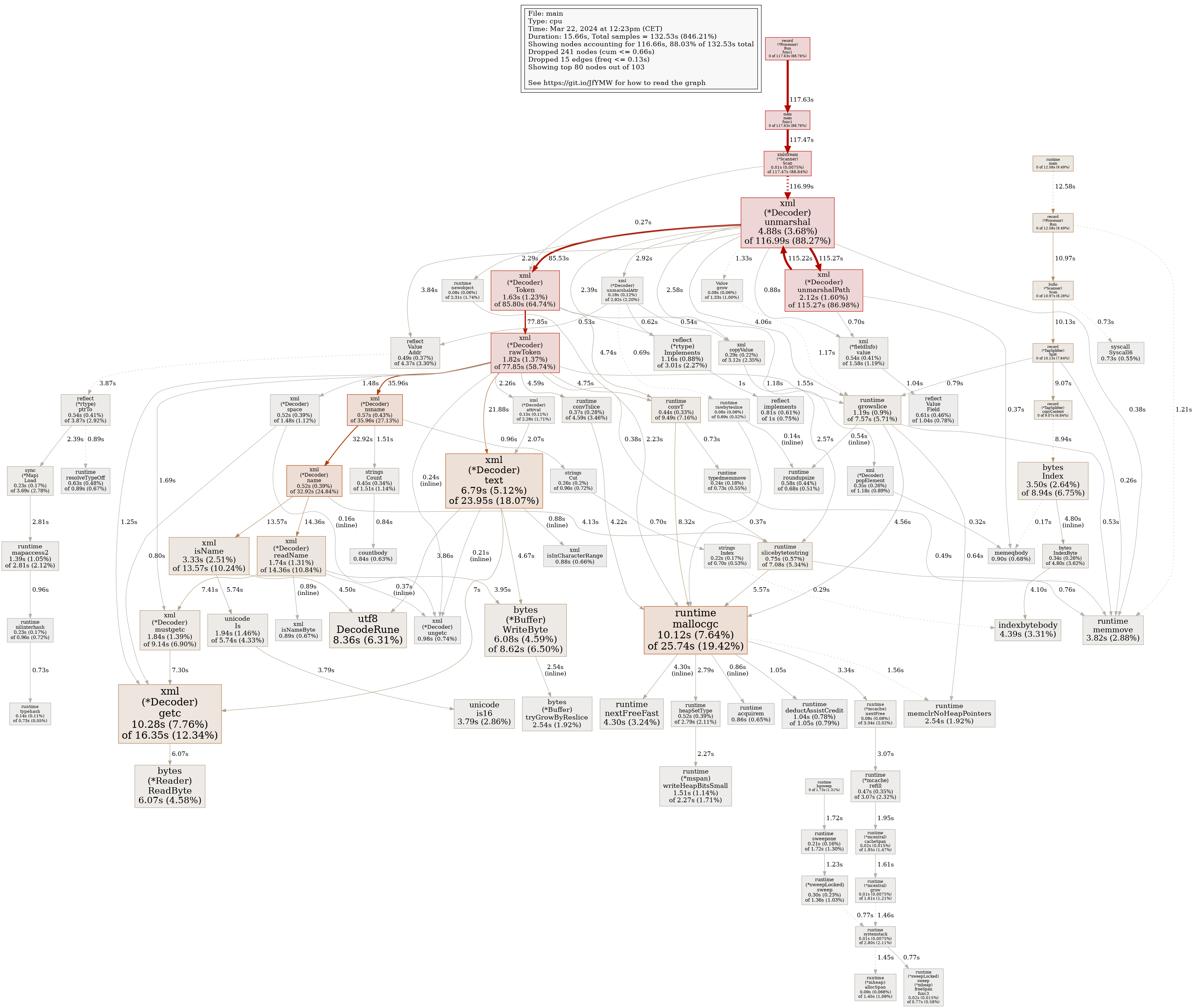
We implemented TagSplitter which will split a stream on XML elements and will batch them into approximately 16MB sized chunks by default (it currently has the limitation that it will not handle nested XML elements of the same name). You can then use standard bufio.Scanner facilities to get smaller batches of valid XML to parse with e.g. xmlstream (an example for parsing complex PubMed XML document can be found here, including a cpu pprof viz showing further, potential performance improvements).
{kind=link}
Anecdata, millions of XML documents
Here is a rough summary of a test run of this approach (using a contemporary CPU) on a dataset consisting of 327GB XML in about 36M documents (36557510) — that is the set of publicly available metadata from PubMed (the target struct requires a few hundred lines). The test ran in 03/2024. The sequential approach takes 177 minutes, the parallel approach brings this down to about 20 minutes, a 9x improvement ⚡ in throughput.
To put this into perspective, you can take a metadata dump of the popular Arxiv preprint server site (hosting about 2.4 million scholarly articles) and parse all of its XML, which amounts to more than 5GB, in about 8s. This makes XML processing more convenient - and fun, again.
PS
Package encoding/xml is not without issues, regarding performance:
{kind=link}